
In the late 1990s, over 5,000 internet startups launched annually, all claiming the “dot-com” mantle. Everyone from web directories to pet supply e-tailers like Pets.com branded themselves as revolutionary platforms. Yet beneath the hype, few distinguished between slapping a “.com” on a basic site and building scalable infrastructure (supply chains, data servers, user retention systems) that could survive without external funding.
The bubble burst in the early 2000s, wiping out $5T in market value and 500+ public companies within two years, exposing the gap between trend-riders and true builders.
- Pets.com epitomized failure, burning $300M with $11M/month revenue; its 56Kbps-era logistics couldn’t handle returns or scale without massive losses.
- Meanwhile, Amazon endured by investing in fulfilment centres, AWS precursors (launched 2002), and data-driven recommendations – proving infrastructure can create defensible moats.
Today’s AI landscape mirrors this, with every company branding itself as “AI-first” (from rule-based chatbots to API wrappers), but few articulate the stack: proprietary data pipelines, causal reasoning beyond LLMs, or feedback loops for continuous improvement. This begs the question – what are the real AI companies that will survive and thrive post this hype era?
Setting the Record Straight
Before examining what AI companies are building today, let’s understand how AI started in the first place
AI dates back to the 1950s, when researchers imagined machines capable of emulating human intelligence. Traditional AI relied on rule-based systems – expert systems with if-then logic, decision trees, and symbolic reasoning. These systems excelled at well-defined problems like playing chess or solving mathematical equations, but lacked adaptability (e.g. a chess engine like IBM’s Deep Blue could not suddenly play Carrom).
The increased traction in the past decade was not because the concept was new, but because three conditions aligned:
- computational power (GPUs),
- data availability (internet-scale datasets), and
- algorithmic breakthroughs (neural networks that could learn representations).
This enabled the shift from rule-based systems to data-driven systems.

(Source)
The confusion between what constitutes an AI/ML/DL/LLM/GenAI starts with terminology. To put it simply-
- Artificial Intelligence refers to systems performing tasks requiring human intelligence e.g. pattern recognition, decision-making, language processing.
- Machine Learning, a subset of AI, involves algorithms that improve through data exposure without explicit programming.
- Deep Learning uses neural networks with multiple layers to automatically extract features from raw data.
- Large Language Models like GPT-4 or Claude represent a specific application: transformers trained on text corpora to generate and process language.
- Generative AI uses models trained on large datasets to create new content such as text, images, code, or audio, rather than just classifying or predicting from existing data.
The distinction matters – a company deploying rule-based automation is not doing ML. A firm using ML for classification is not necessarily working with LLMs. A business calling Claude’s API is not building AI infrastructure. The distinction is the difference between Spotify (building recommendation engines and licensing infrastructure) and a playlist curator (arranging existing content).
Smarter, Better, Faster, Stronger
The current AI arms race centres on scaling LLMs – larger models, longer context windows, more parameters. But this approach has fundamental limitations that increased computation cannot solve.
The limitations become clear through Moravec’s paradox – the observation that it is easier to teach AI systems higher-order skills like playing chess or passing standardized tests than basic human capabilities like perception and movement. LLMs have mastered language without learning foundational abilities.

Illustration of Moravec’s Paradox: Source
As Yann LeCun (often called the godfather of modern AI) highlights – “We have these language systems that can pass the bar exam, can solve equations, compute integrals, but where is our domestic robot?” , suggesting that LLMs will become obsolete within five years, highlighting the need for alternative approaches like world models that can comprehend how the real world works so it can predict and prepare for future situations like humans
The economic constraint is further compounded by the technical one.
- Consider Mike Ross’s character from popular show Suits, who possessed photographic memory. His ability to recall case law instantly gave him an edge, but memory alone did not make him a lawyer. He needed judgment, strategy, and context.
- LLMs face the same constraint. Expanding context windows improves retrieval but increases inference costs proportionally.
- For consumer applications, this works.
- For enterprise the unit economics break down.
- Retrieval-Augmented Generation (RAG) helps in the above, but introduces latency and requires maintaining separate vector databases. Retrieval is not reasoning.
The next generation requires different architectures. Recursive Language Models (RLMs) represent one promising direction
- Instead of linear processing, these systems break complex problems into smaller sub-queries until they are simple enough to solve accurately.
- The model creates a structured task tree, focusing on one piece at a time without losing context of the overall goal.
- This recursive approach forces AI to move from “guessing the next word” to “programmatically breaking down a problem” using self-referential logic with early results showing improvement over traditional approaches on coding and mathematical reasoning.
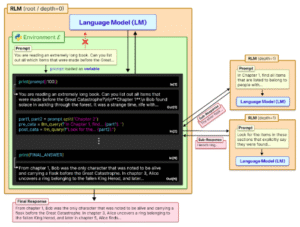
Recursive Language Models Approach (Zhang, Kraska, Khattab) via MIT (Source)
Companies investing in these capabilities – whether world models or RLMs are building moats. Those optimizing prompts are renting capability.
AI: Auxano Intent
At Auxano, we distinguish between using AI and building AI capabilities not only for investments and our existing portfolio but also for optimizing our internal operations
- Internal Ops: We deploy LLMs for summarization, extraction, document review and DD review, but pair them with verification systems. The AI suggests; humans validate, utilising our human in the loop approach highlighted here.
- Portfolio AI: Our portfolio companies use AI across this spectrum. Some build proprietary technologies for specific domains (such as Mugafi building an integrated system for creating + monetising + producing content IPs) while others integrate existing models into workflows such as
- ClicFlyer – Customised insights on brand campaigns through AI + ML workflows,
- Private Circle – ML enabled private market intelligence + deal facilitation
- Adloggs – Optimising deliveries and fleet utilisation via own APIs + external integrations.
- Investment Evaluation: We assess whether companies have the data pipelines, processes, and feedback loops required for AI deployment. Some questions we look at include
- Does the company have proprietary training data?
- Are models improving through production feedback?
- What happens if competitors access the same foundation models?
A company with clean, labelled data and continuous improvement cycles has an advantage over one with sophisticated models but low data hygiene.
Takeaway
The dot-com crash separated trend-riders from those with actual value propositions. AI will follow a similar pattern. Understanding what constitutes genuine AI capability provides a framework for evaluating opportunities:
- Companies building proprietary data pipelines and feedback loops create defensibility.
- Businesses deploying LLMs for feature parity face commoditization as models improve.
- Firms with leverage (distribution, data, people) or those investing in frontier tech (world models, recursive architectures etc.) will build moats beyond current paradigms.
As for identifying the real AI companies, just remember – when the music stops, only those with a real value proposition will still be standing.
Author,
Aditya Golani
